Garbled Email, Round 1B 2013.
This is a tricky problem. The first tricky part is figuring out an efficient way to store the dictionary so that we can quickly identify whether a particular substring is a prefix of a word in the dictionary. This is a well-studied problem, and the right data structure is a trie. Suppose we’re working with a small dictionary containing the words a, aac, acb, baa, bbc, bc, caba, caab. We’ll start our trie with an empty node, and then keep adding words until we’re finished. We start by adding the word a. We link a node with the letter a to the root, and then link a marker node to that to show that this is the end of a word.

Next, we’ll add in the word aac. We already have the letter a linked to the root, so we go there and add more letters to that node.

And we repeat this until all the words are in the tree. For each letter in the new word, if that letter is already a child of the current node, we walk to that child. If not, we create a new child. Once we’re at the end of the word, we add a marker child to the last node denoting the end of the word. After we’re finished with our small dictionary, we end up with this:
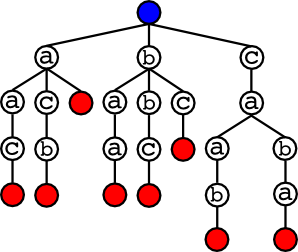
Each of the red nodes marks the end of a word, so we can see that we have all eight words in the trie.
Now that we have our data stored in an easily-accessible manner, let’s start with a simpler problem than the one asked. Suppose that there was no garbling, just spaces removed, and we’re given some string, say, aacaabbc. How can we use this structure to quickly find out whether this string could be divided up into words from our dictionary? Start at the root of the tree and look at the first letter a of the string. a is a child of our current node, so we’ll walk to that node and move to the next letter. Here we see an end node as a child, marking that we’ve now finished a possible node. So we know we can split off the word a from our string, leaving acaabbc behind. This split will produce a valid word separation for the whole string if and only if acaabbc can itself be divided up into words from our dictionary.
First, though, we need to finish walking down and make sure we’ve found the only possible split. The next letter is a, which is a child of our current node, so we move there. This node has no end node as a child, so it’s not a possible word separation. The third letter is c, which is a child of this node, so we’ll move there next. This node is another word separation, giving us aac as the first word and aabbc as the remainder of the string. There are no other children of this node, so these are the only possible word separations.
So we now know that aacaabbc is divisible into words if and only if at least one of its two suffixes acaabbc and aabbc are divisible into words. This suggests that we might be able to use dynamic programming for our problem. We can create an array of boolean variables telling us whether each suffix of our string can be divided into words. We can look at the suffixes of our string in order of increasing size and calculate whether each of them is divisible. The larger suffixes can then use the calculations previously done on the smaller suffixes to quickly calculate whether they themselves are divisible.

Starting with the smallest suffix, c, we quickly find that it is not a word, so we mark that index as False. bc, the next smallest, so we mark it as True, and similarly for bbc. abbc gives a potential split at a|bbc, and we know that bbc is True, so abbc must be True as well. We then keep working backwards until we reach the beginning of the string, and then the final answer is simply the result in the first element of our array. Doing this we quickly find that aacaabba is in fact divisible.
So this works for messages where there is no garbling at all. Now let’s add the garbling in and see if we can work out a solution. We’ll simplify the problem slightly, though, by allowing any character in the string to be garbled, ignoring the constraints on how close the garbled characters are allowed to be. Suppose we have the string abbbcbba. We can work backwards, just as before, from smaller to larger suffixes. This time, though, instead of only storing whether or not a suffix is divisible into words, we’ll store how many changes are needed to make it divisible.
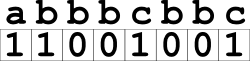 c alone, for instance, isn’t a word, but we can change it into a with a single substitution, so our answer is one. The next two suffixes, bc and bbc, are both words, so they get values of zero. cbbc isn’t valid, but if we swap it to abbc we can split it at a|bbc, giving us two valid words, for an answer of one. We keep working backwards just as before, looking for all possible words we can construct at the start of our suffix, splitting it, and then putting the minimum changes required into our array. Once we’re finished, the final answer is just the result in the first element of our array. So we find that abbbcbbc can be made divisible with only a single character swap.
c alone, for instance, isn’t a word, but we can change it into a with a single substitution, so our answer is one. The next two suffixes, bc and bbc, are both words, so they get values of zero. cbbc isn’t valid, but if we swap it to abbc we can split it at a|bbc, giving us two valid words, for an answer of one. We keep working backwards just as before, looking for all possible words we can construct at the start of our suffix, splitting it, and then putting the minimum changes required into our array. Once we’re finished, the final answer is just the result in the first element of our array. So we find that abbbcbbc can be made divisible with only a single character swap.
Finally, we want to incorporate the closeness requirements for our garbled characters – changes must have at least four non-garbled characters between them. Now for each suffix we want to store five different values, giving the minimum changes required for this suffix when the first x characters are required to match perfectly, with x ranging between 0 and 4 inclusive. Let’s look at this array for the string abbbcbba.

Here N is marking divisions that are not possible at all. Otherwise, we fill the array with the number of changes required. Again, let’s start at the back and move towards the front of the string. a, the last suffix, is a word itself, so we fill its column with zeros. ba is not a word, but could be divisible if we change one of the characters, to either bc or a|a. The bottom three rows require us to keep the first two characters unchanged, so those entries are marked as N. Both of the top two are possible with only a single change. bba is valid only if changed into bbc, which requires no more than two characters held unchanged, so we mark up the column appropriately. We continue in the same manner, looking for potential word divisions and marking down the minimum changes required that allow the required distance between changes. Then, just as with the simpler problems, we read off our final answer as the entry in the first column and the first row. Continue reading →


 . Of those blocks that are larger, he should use the smallest, because that will allow the larger blocks to be used later and potentially win more rounds. If he has no blocks larger than
. Of those blocks that are larger, he should use the smallest, because that will allow the larger blocks to be used later and potentially win more rounds. If he has no blocks larger than 






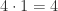 total possible substrings containing this stretch.
total possible substrings containing this stretch. . Then there are
. Then there are  possible positions for the start of substrings containing this stretch (all indices from 0 to i inclusive) and
possible positions for the start of substrings containing this stretch (all indices from 0 to i inclusive) and  possible positions for the end of substrings containing this stretch (all indices from j to L – 1 inclusive). Since these choices of start and end positions are independent, that gives us
possible positions for the end of substrings containing this stretch (all indices from j to L – 1 inclusive). Since these choices of start and end positions are independent, that gives us 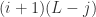 possible substrings.
possible substrings.
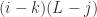 new substrings containing this stretch of consonants. If we do this with i, j, k = 5, 7, 0 for the second substring, we get 5, which gives us the correct answer when added to the 6 substrings containing the first substring.
new substrings containing this stretch of consonants. If we do this with i, j, k = 5, 7, 0 for the second substring, we get 5, which gives us the correct answer when added to the 6 substrings containing the first substring.
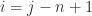 . We then substitute this into our last expression, giving the number of additional substrings contributed by each stretch of consonants as
. We then substitute this into our last expression, giving the number of additional substrings contributed by each stretch of consonants as  .
. with a mote of size
with a mote of size 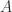 is
is
 , where A can never grow and we must remove all motes and
, where A can never grow and we must remove all motes and  , where there are no motes remaining, and we simply return 0. For other cases, if we can eat the first mote, then we recursively call with
, where there are no motes remaining, and we simply return 0. For other cases, if we can eat the first mote, then we recursively call with  and
and  , and the recursive call with
, and the recursive call with  .
.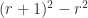 units of paint, the second
units of paint, the second 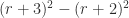 units, and so forth, so that the
units, and so forth, so that the  ring will require
ring will require , or
, or
 ) plus some varying amount depending on how far out it is (
) plus some varying amount depending on how far out it is ( ). That second sequence is 1, 5, 9, 13, 17, 21, etc. But the question we want to answer is not how much paint each ring will take, but how many rings we can paint with a given amount of paint.
). That second sequence is 1, 5, 9, 13, 17, 21, etc. But the question we want to answer is not how much paint each ring will take, but how many rings we can paint with a given amount of paint. , and
, and 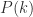 from 1 to k. We first note that there is a constant amount of paint for each ring, so we can sum up that part simply as
from 1 to k. We first note that there is a constant amount of paint for each ring, so we can sum up that part simply as  . The first few variable sums are 1, 6, 15, 28, 45…, which we can recognize as the sequence of
. The first few variable sums are 1, 6, 15, 28, 45…, which we can recognize as the sequence of  . This gives us:
. This gives us:
 , the total amount of paint we have, for
, the total amount of paint we have, for  , solve for
, solve for 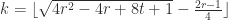
 while
while  . Simply walking through increasing values of
. Simply walking through increasing values of  . So let’s start a lower limit for our search at
. So let’s start a lower limit for our search at  . We’ll start an upper limit at
. We’ll start an upper limit at  . It’s probably not an upper limit yet, but we’ll make it so by iteratively doubling both our limits until it is: find the first power of 2 where
. It’s probably not an upper limit yet, but we’ll make it so by iteratively doubling both our limits until it is: find the first power of 2 where 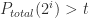 . Then
. Then  . We can find its exact value by repeatedly subdividing this interval until it is narrowed down to a single value.
. We can find its exact value by repeatedly subdividing this interval until it is narrowed down to a single value.